| Montando um Cluster com Kerrighed |
|
| Ter, 28 de Abril de 2009 01:39 | ||||||||||||||||||||||||||
|
O kerrighed é um sistema operacional de imagem única (Single System Image Operating System – SSI OS) que estende o kernel do Linux e tem como objetivo a construção de clusters de, principalmente, alto desempenho e alta disponibilidade. Ele oferece aos usuários a ilusão de que os nós são grandes maquinas SMP, que dispõem da soma de todos os recursos disponíveis nos computadores que compõem o cluster. Este relatório mostra, passo-a-passo, como implementar um cluster usando o kerrighed e usufruir do poder de processamento da sua rede.
Introdução
Um sistema SSI proporciona uma visão unificada de todos os recursos e atividades em execução no cluster, possibilitando abstrair ao usuário o caráter distribuído, não precisando ele sequer saber que usufrui de um cluster. A distribuição de carga é feita de forma automática e não exige que os processos tenham sido escritos especificamente para sistemas distribuídos (com uso de bibliotecas específicas, como MPI), podendo estes migrarem livremente para quaisquer dos nós. No projeto de implementação de um cluster, é imprescindível que sejam levantadas as suas reais necessidades, bem como as suas aplicações finais, a fim de que não seja desperdiçado poder de processamento com atividades que poderiam ser solucionados por um único computador (com menor consumo de energia, por exemplo). Este relatório é fruto da implementação de um protótipo de cluster no laboratório Ada de Lovelace do Departamento de Informática – DI/UFPB, e tem como objetivo futuro atender aos usuários que desejam ampliar seus conhecimentos em desenvolvimento para arquiteturas distribuídas e auxiliar em tarefas “pesadas”, como processamento digital de imagens, renderização de moldes e cenas 3D e demais tarefas desta natureza que são rotineiras no departamento de informática. Outra possível aplicação útil pode ser feita nos servidores de uma rede, a fim de oferecer alta disponibilidade, além de elevar o desempenho.
Considerações Iniciais
Dentre as versões do kerrighed, foram testadas duas em desenvolvimento (corrente) e a versão estável, tendo sido uma versão intermediária a mais indicada, por ter resolvido problemas presentes na ultima release lançada e não apresentado as falhas da corrente mais recente. A distribuição do Linux usada foi o Ubuntu, por ser a utilizada atualmente no laboratório Ada de Lovelace, do Departamento de Informática – DI/UFPB, no qual o protótipo foi montado. Foram realizados testes com as versões 3.3, 4.1, 4.2 e 4.3 do compilador GCC e, apesar da documentação oficial do projeto sugerir a versão 3.3 para todo o processo de compilação, a prática mostrou que a versão 4.1 se mostrou mais indicada, com a qual foi possível compilar todas as etapas sem muitos problemas e por fim não obter falhas de segmentação, que ocorriam ao usar o gcc-3.3, e demais erros.
Instalando o Cluster
Antes de prosseguir, se faz-se necessário resolver alguns futuros problemas com dependências. Sugere-se a instalação dos seguintes pacotes:
#apt-get install ncurses-dev #apt-get install subversion #apt-get install automake #apt-get install autoconf #apt-get install libtool #apt-get install pkg-config #apt-get install gawk #apt-get install rsync #apt-get install lsb-release #apt-get install xmlto #apt-get install patchutils patch #apt-get install xutils-dev #apt-get install build-essential #apt-get install make
Quadro 1: Instalando dependências.
Para instalar o gcc-4.1, a dependência abaixo deve ser adicionada ao arquivo /etc/apt/sources.list: deb http://cz.archive.ubuntu.com/ubuntu dapper main Em seguida, é preciso sincronizar os pacotes com a nova dependência para posterior instalação: #apt-get update #apt-get install gcc-4.1 #apt-get install g++-4.1
#cp /usr/bin/gcc /usr/bin/gcc.old #ln –s /usr/bin/gcc-4.1 /usr/bin/gcc
A instalação do kerrighed, usando uma versão do svn, pode ser iniciada acordo com os comandos abaixo: #svn checkout svn://scm.gforge.inria.fr/svn/kerrighed/trunk /usr/src/kerrighed -r 4762 #./autogen.sh Quadro 2: Resumo da instação.
Na versão estável 2.3.0 fazia-se necessário baixar o source do kernel Linux 2.6.20, a fim de que o microkernel kerrighed pudesse estendê-lo. Na versão em desenvolvimento, disponível via svn, na qual se baseia este guia, o source do kernel pode ser encontrado dentro do subdiretório kernel/, o qual deverá ser configurado de acordo com as necessidades e particularidades do cluster, devendo ser dada atenção a correta configuração da interface de rede, bem como os módulos de suporte a NFS, como a seguir:
#cd kernel #make menuconfig
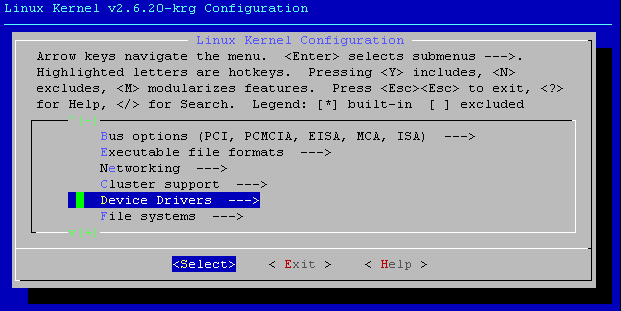
Será apresentado ao usuário o menu de configurações do kernel (percebe-se, na parte superior, a sigla –krg junto ao nome da versão do kernel) ilustrado na figura 1. Como já mencionado, é indispensável ativar o suporte à interface de rede – além de configurações particulares de cada caso - que pode ser feito de acordo com o caminho abaixo: Device Drivers -à Network device suport -à Escolha a categoria da sua interface [ex: Ethernet ( 10 or 1000Mbit ) ] -à Selecione seu modelo ( ex: AMD PCnet32 PCI support, Intel(R) PRO/100+ support, Realtek, VIA, etc ).
Figura 1 – Configuração do kernel
Concluído as modificações no kernel, deve-se pressionar a tecla [ESC] duas vezes em cada menu até que seja perguntado se as alterações devem ser salvas, devendo-se escolher a opção YES para salvá-las. Se não houver muita familiaridade da parte do usuário com o kernel, pode-se ainda optar por usar um arquivo pré-definido de configurações, que dispensará a configuração manual da interface de rede (realizada logo acima), além de outras configurações ( usar um arquivo de configuração sem os devidos cuidados pode acarretar em erros pós-instalação). Um arquivo de configuração para este caso pode ser obtido como abaixo: #wget http://trac.nchc.org.tw/grid/raw-attachment/wiki/krg_DRBL/config-2.6.20-krg
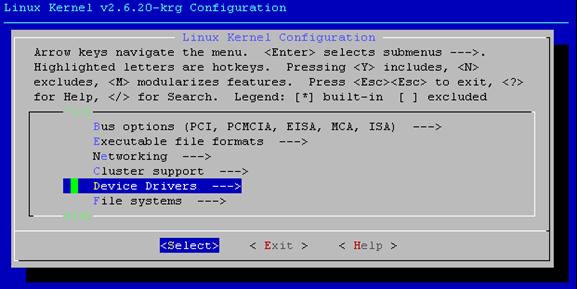
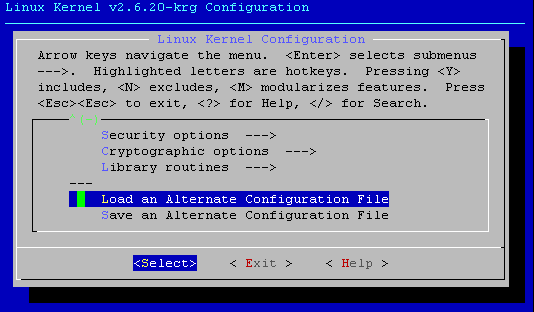
Em seguida, carrega-se o arquivo no kernel, como pode ser visto nas linhas seguintes e nas figuras 2 e 3: #make menuconfig Load an Alternate Configuration File Digite o nome do arquivo de configuração: config-2.6.20-krg Tecle [ENTER], [ESC] duas vezes para sair e salve as alterações.
Figura 2 – Carregar arquivo de configuração do kernel
Figura 3 – Definindo arquivo de configuração
Uma vez atendido aos passos acima, pode-se compilar o kernel e prosseguir com a instalação. Durante a compilação diversos erros podem ocorrer, os quais serão resolvidos passo-a-passo no decorrer do guia:
#cd ..
Erro 1:
Erro 2:
Se não ocorreram erros, prossegue-se com o comando seguinte:
#make CC=gcc-4.1
O passo acima poderá retornar, de acordo com os testes, dois erros, que não precisam estar na ordem exposta abaixo, mas que podem ser solucionado de acordo com os seguintes passos:
Erro 3
Provavelmente neste ponto o kernel será compilado sem mais problemas, porém, se não foi utilizado o gcc-4.1, ainda existe a possibilidade de outro erro ocorrer:
Erro 4:
Concluído o passo anterior, o cluster está a um passo de ser compilado. Pode-se finalizar com os comandos abaixo, os quais não deverão retornar erros se os requisitos anteriores tiverem sido atendidos:
Ao fim do make install, o novo kernel está pronto e sua imagem deve ter sido criada em /boot/vmlinuz-2.6.20-krg. Para testar o novo nó do cluster, deve-se adicionar a nova imagem em uma entrada no seu gerenciador do boot, conforme o procedimento abaixo para o grub:
Adicionar as linhas abaixo: title Kerrighed Cluster (ubuntu) kernel /boot/vmlinuz-2.6.20-krg root=/dev/sda1 ro session_id=1 node_id=1
OBS: root=/dev/sda1 indica a partição raiz. Em alguns casos, ainda que sua raiz seja reconhecida como sda, talvez seja necessário usar hda. Este problema foi reportado em alguns dos computadores do laboratório Ada. Caso o boot não seja efetuado corretamente (terminando em um Shell ram), é provável que se deva alterar sda1 para hda1 no menu.list. session_id=1: indica a sessão na qual este nó será inserido. node_id: identificação do nó. Cada qual deverá ter seu próprio id.
Confirma-se as alterações:
#update-grub
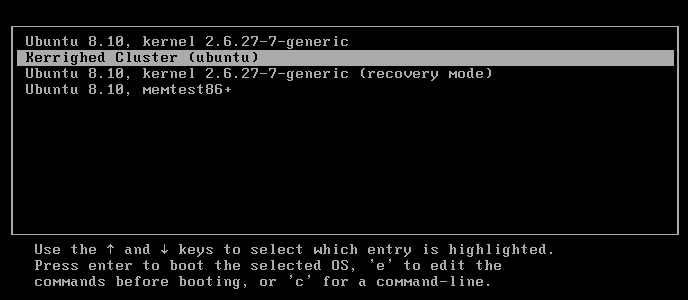
Se não ocorreram erros, o primeiro nó está pronto. Ao reiniciar o computador, escolhe-se a nova entrada no grub, conforme figura 4.
Figura 4 – Iniciando cluster pelo grub
A versão do kernel pode ser verificada digitando: #uname –r Que deverá retornar “2.6.20-krg”
Gerenciamento
O gerenciamento é feito pelo “krgadm”. Digita-se man krgadm para verficar o seu manual. Em resumo, os seguintes comandos são suficientes:
Exibe o status dos nós disponíveis: #krgadm nodes
Exibe informações sobre a inicialização da(s) sessões: #krgadm cluster
Para iniciar o cluster, usa-se o comando abaixo, que irá inicializá-lo com todos os nós: #krgadm cluster start
Uma vez inicializado, os processos serão distribuídos automaticamente pelos nós do cluster.
Adicionando mais nós
Uma vez instalado, diversas abordagens podem ser feitas de acordo com o contexto e as necessidades específicas atribuídas ao cluster. Em um laboratório público, por exemplo, onde os computadores devem estar disponíveis para diversos fins, pode-se usar o cluster descentralizado, onde cada um dos nós será instalado seguindo os mesmos passos acima expostos e garantindo, assim, a independência de cada nó. Desta forma, uma vez iniciado o cluster (krgadm cluster start), os processos executados em qualquer dos nós serão distribuídos aos demais, sendo abstraído aos usuários o processo de migração. Cada um dos computadores se comportará como uma grande maquina SMP, dispondo da soma de todos os recursos distribuídos. Apesar da cansativa instalação dos nós, o modelo descentralizado pode ser facilmente alcançado usufruindo de métodos que visam acelerar o processo. Um exemplo é a utilização de um fast install, que possibilita replicar, sem muito esforço, toda configuração de uma maquina para todas as demais em uma rede, semelhante a uma clonagem de disco, porém mais bem elaborada. Concluído o processo de fast install, os nós só precisam ser ajustados quanto a configurações específicas, como IP e node_id, a fim de se integrarem corretamente ao cluster, que já estará disponível.
Nós sem disco rígido
Outra abordagem geralmente adotada quando não há necessidade de que os nós, exceto o central, estejam disponíveis para usuários, é a utilização destes sem um disco rígido. Este tipo de cluster normalmente é preferível, porém ressalta-se mais uma vez que o método escolhido deve levar em consideração as necessidades do laboratório. Para este método, pode ser usada uma instalação mínima do sistema no nó central, a qual será utilizada pelos demais nós, compartilhada via TFTP; que disponibilizará a imagem do kernel e configurações de boot, NFS; que exportará o sistema de arquivos, possibilitando que este seja montado remotamente e um servidor DHCP; que fará a configuração automática dos nós, elevando, desta forma, a escalabilidade do cluster.
O quadro 4 demonstra a configuração para uso através de um sistema mínimo de arquivos. Caso se deseje aproveitar a instalação realizada na seção 1, pode-se seguir adiante e pular este quadro.
Quadro 4: Instalando um sistema mínimo de arquivos (chroot)
O compartilhamento do sistema de arquivos pode ser configurado de acordo com os passos abaixo.
Iniciar o computador escolhendo, no grub, o kernel do kerrighed e instalar os serviços: #apt-get install dhcp3-server nfs-kernel-server nfs-common tftpd-hpa syslinux
Configurando TFTP
Copiar a imagem do kernel para o diretório do tftp: #cp /boot/vmlinuz-2.6.20-krg /var/lib/tftpboot
Copiar arquivo pxelinux.0 para o diretório do tftp, necessário para o boot via rede: #cp /usr/lib/syslinux/pxelinux.0 /var/lib/tftpboot
Criar diretório que disponibilizará os arquivos com as configurações necessárias para que os nós iniciem corretamente: #mkdir pxelinux.cfg
A documentação do kerrighed instrui a criação de um arquivo default, no diretório criado acima, que conterá as configurações de boot para os nós, semelhante a um grub, porém via rede. O conteúdo deste arquivo de configuração pode ser visto abaixo: ### /var/lib/tftpboot/pxelinux.cfg/default ###
default cluster label cluster kernel /vmlinuz-2.6.20-krg append console=tty1 root=/dev/nfs initrd=/initrd.img-2.6.20-krg nfsroot=<IP_DO_NÓ_CENTRAL>:/ ro ip=dhcp pci=nommconf session_id=1
######
Porém, esta abordagem reduz a escalabilidade do cluster, visto que um só arquivo será utilizado por todos os nós durante o boot, não sendo possível, assim, configurar-se o node_id específico de cada um dos nós automaticamente. Repare que no nó central, esta configuração é feita no arquivo menu.list do grub, após session_id. Uma solução para esse problema é disponibilizar um arquivo de configuração para cada um dos nós, o qual irá atribuir o node_id durante o boot, a fim de que o nó se integre ao cluster sem a necessidade de posterior configuração. O TFTP pode atribuir, automaticamente, um arquivo de configuração para cada nó de acordo com o IP, porém para que este “casamento” entre arquivo e nó seja bem sucedido, é necessário, também, que os nomes dos arquivos sejam iguais aos respectivos IPs dos nós, em hexa-decimal. O exemplo abaixo pode esclarecer melhor a situação:
Nó 2 recebe IP: 192.168.0.4 ßà TFTP envia arquivo de configuração: C0A80004 (o IP em hexa) Nó 3 recebe IP: 192.168.0.132 ßà TFTP envia arquivo de configuração: C0A80089 (o IP em hexa) E assim por diante.
Isto significa que o TFTP terá que ter um arquivo para cada possível IP atribuído pelo DHCP. Essa tarefa pode ser facilmente auxiliada por um script/programa que os gere, cada qual com um node_id diferente. Foi escrito um programa em java com esse objetivo, que pode ser obtido no link: www.joaomatosf.com/files/ConvIpHexa.jar e seu código segue no quadro 5.
Quadro 5: Programa em Java para gerar os arquivos de configuração do TFTP automaticamente:
Para gerar os arquivos de configuração com o programa, é necessário informar apenas o diretório raiz do sistema (que será exportado mais adiante pelo NFS), a faixa de IPs que será usada pelo cluster e o IP do nó central. Os passos abaixo demonstram essa configuração:
#java –jar ConvIpHexa.jar Diretório NFS compartilhado[ex: /NFSROOT/kerrighed]: / [ENTER] Faixa de IPs para os nós[ex: 192.168.0]: 192.168.0 [ENTER] IP do servidor NFS[ex: 192.168.0.1]: 192.168.0.1 [ENTER]
O programa irá gerar um arquivo para cada IP da faixa informada, os quais deverão ser movidos para o diretório /var/lib/tftpboot/pxelinux.cfg.
Configurando NFS
O NFS é responsável por permitir a montagem remota dos diretórios como se fossem diretórios locais. Sua configuração é simples e feita no arquivo /etc/exports.
Abre-se o arquivo de configuração e adiciona-se as linhas abaixo: #pico /etc/expots
### /etc/exports ###
/ *(rw,no_root_squash,no_subtree_check,async,fsid=1) /tmp *(rw,sync,no_root_squash,no_subtree_check) /var *(rw,sync,no_root_squash,no_subtree_check) /root *(rw,sync,no_root_squash,no_subtree_check) /etc *(rw,sync,no_root_squash,no_subtree_check)
######
Caso se deseje limitar a faixa de IPs que poderá montar os diretórios remotos, pode-se substituir os “asteriscos” pela faixa pretendida, de acordo com o exemplo abaixo: / 192.168.0.0/255.255.255.0(rw,no_root_squash,no_subtree_check,async,fsid=1)
Após alterar o arquivo exportfs, o seguinte comando deve ser usado para pôr as modificações em vigor: #exportfs –avr
Configurando fstab e initrd
O arquivo /etc/fstab deverá refletir os diretórios exportados pelo NFS, a fim de que estes sejam montados durante o boot dos nós remotos. Deve-se criar um backup do arquivo original e um novo com o seguinte conteúdo:
#mv /etc/fstab /etc/fstab.old #vi /etc/fstab
none /proc proc defaults 0 0 none /sys sysfs defaults 0 0 none /var/run tmpfs defaults 0 0 /var /var nfs rw,soft,nolock 0 0 /tmp /tmp nfs rw,soft,nolock 0 0 /root /root nfs rw,soft,nolock 0 0 #we need this as rw to setup ssh (refer to our ramdisk.sh script) /etc /etc nfs rw,soft,nolock 0 0 /dev/nfs / nfs defaults 0 0
Após a alteração acima, deve-se gerar um novo initrd que seja capaz de montar os diretórios remotos durante o boot.
No arquivo: #vi /etc/initramfs-tools/initramfs.conf Substitui-se a linha: BOOT=local Pela linha: BOOT=nfs
Em seguida, deve-se gerar o novo initrd: #mkinitramfs –o /var/lib/tftpboot/initrd.img-2.6.20-krg 2.6.20-krg
Este initrd carrega os módulos necessários para o computador iniciar e montar os diretórios do fstab. Porém, além dos módulos necessários para iniciar o PC, deve-se também garantir que o modulo kerrighed, necessário para funcionamento do cluster, seja carregado automaticamente durante o boot, de acordo com os passos abaixo:
No arquivo /etc/modules, adiciona-se a linha dos módulos que se deseja carregar: #vi /etc/modules # /etc/modules: kernel modules to load at boot time. # # This file contains the names of kernel modules that should be loaded # at boot time, one per line. Lines beginning with "#" are ignored. Kerrighed
Configurando DHCPD
O servidor DHCP é o serviço responsável por informar aos nós o arquivo pxe de configuração, além de lhes atribuir os IPs. Existem diversas configurações possíveis para um servidor dhcp, onde, normalmente, pode-se “amarrar” IPs aos MACs, informar configurações específicas para cada nó, entre outras. A configuração julgada mais viável para este tipo de aplicação é feita em poucas linhas, que seguem abaixo:
Cria-se um backup do arquivo de configurações original: #mv /etc/dhcp3/dhcpd.conf /etc/dhcp3/dhcpd.conf.old
Gera-se o novo arquivo com o seguinte conteúdo: #vi /etc/dhcp3/dhcpd.conf allow booting; allow bootp;
# What IP range to serve: subnet 192.168.0.0 netmask 255.255.255.0 { range 192.168.0.2 192.168.0.250; option broadcast-address 192.168.0.255;
# MTU (possibly lower than 1500 to walk through NATs): option interface-mtu 1500;
# IP do servidor next-server 192.168.0.1;
# Eventual section for the server (disconnected mode):
# TFTP image: filename "pxelinux.0";
} Devendo-se alterar as faixas de IPs, bem como o IP do servidor, de acordo com as configurações da rede local.
Considerações e Testes Finais
Para testar o cluster, é necessário reiniciar os serviços instalados anteriormente no nó central: #/etc/init.d/dhcp3-server restart #/etc/init.d/nfs-kernel-server restart #inetd É importante frisar que para o servidor dhcp ser executado normalmente, é necessário que o IP do servidor seja o mesmo informado no arquivo de configuração do dhcp. Também é aconselhável desativar o ambiente gráfico, caso este não vá ser utilizado: #update-rc.d –f gdm remove Para reativar, use: #update-rc.d gdm defaults
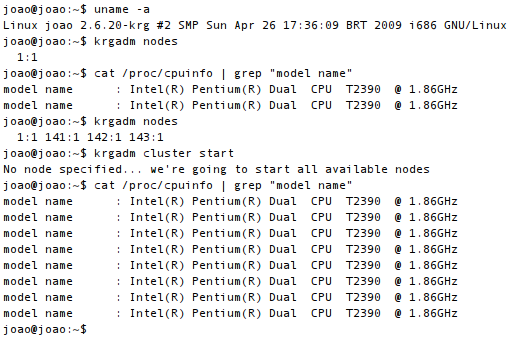
Iniciado os serviços, basta ligar os computadores, configurados para realizarem o boot pela rede, e aguardar que sejam iniciados. A figura 5, a seguir, ilustra o funcionamento do cluster.
Figura 5 – Iniciando o cluster e exibindo processadores disponíveis
Ao rodar o comando top e pressionar a tecla 1, apresenta-se o resumo dos processadores disponíveis e a carga utilizada. Talvez seja necessário informar, pelo arquivo /etc/kerrighed_nodes, os nomes dos hosts com seus respectivos node_ids, de acordo com o exemplo abaixo: No1:1:eth0 No2:2:eth0 E assim por diante.
Conclusão
Clusters SSI são boas alternativas de baixo custo, que possibilitam atingir excelentes níveis de disponibilidade, performance e escalabilidade para aplicações de risco. Com a descontinuidade do OpenMosix, o kerrighed tem se mostrado uma excelente alternativa e que vem evoluindo a um nível rápido, dado os esforços da equipe de desenvolvimento. Por conta da complexidade desse tipo de projeto, raramente se tem versões que conseguem acompanhar a velocidade de desenvolvimento do kernel linux, daí a necessidade de se usar suas versões anteriores, o que pode reduzir a compatibilidade e quantidade recursos disponíveis se comparado ao oferecido pelas versões mais nova do kernel linux. Outra modalidade de cluster que vem crescendo são os baseados na biblioteca MPI, que permitem aos programadores escreverem programas específicos para este tipo de sistema distribuído, que trabalha com a troca de mensagens, embora esse tipo de cluster, diferente dos SSIs, necessitem de aplicações específicas para ele. O kerrighed mostrou-se estável e confiável, sendo satisfatório os resultados dos testes realizados no Departamento de Informática – DI/UFPB, tendo sido considerado um bom modelo para atender às necessidades de processamento “pesado” e disponibilidade dos servidores.
Referencias
Kerrighed on NFSROOT. Disponível em http://www.kerrighed.org/wiki/index.php/Kerrighed_on_NFSROOT_(contrib) Booting On PXE ... Partimage. Disponível em http://www.howtoforge.com/forums/archive/index.php/t-20887.html Tutorial: Kerrighed. Disponível em http://bioinformatics.rri.sari.ac.uk/drupal/?q=wiki/tutorial_kerrighed Ubuntu Forums. Disponível em http://ubuntuforums.org/showthread.php?p=6979803
Somente usuários registrados podem escrever comentários!
!joomlacomment 4.0 Copyright (C) 2009 Compojoom.com . All rights reserved."
|